
nvidia از سه سال پیش تاکنون، تراشههایی را تولید میکند که دارای هستههای اضافی در کنار هستههای عادی Shader (هستههای مخصوص سایه زنی) هستند. این واحدهای مرموز که بهعنوان هستههای تنسور شناخته میشوند را میتوان در هزاران رایانه رومیزی، لپتاپ، ورک استیشنها و مراکز داده در سراسر جهان یافت.
اما آنها دقیقاً چه هستند و برای چه استفاده میشوند؟ آیا واقعاً به وجود آنها در کارت گرافیک نیاز دارید؟ در این پست از اگزوگیم به این موضوع میپردازیم تا بفهمیم چگونه هستههای تنسور در دنیای گرافیک و یادگیری عمیق استفاده میشود.
مرور کوچکی بر ریاضی
برای فهمیدن اینکه هستههای تنسور دقیقاً چه کاری انجام میدهند و در چه مکانی میتوانند استفاده شوند باید اول بفهمیم که هستههای تنسور چه هستند. در ابتدا، باید بدانید ریزپردازندهها بدون درنظرگرفتن ساختار و فرم برای انجام عملیات ریاضی روی اعداد، مثل جمع، ضرب، تقسیم و ... ساخته شدهاند.
گاهی اوقات اعداد معنای خاصی برای هم دارند و باید با یکدیگر گروهبندی شوند. برای مثال پردازشگر وقتی مشغول رندر جلوهها و تصاویر گرافیکی میشود، گاهی اوقات باید از اعداد صحیح برای محاسبه مقیاس استفاده کند یا در فضاهای سهبعدی برای محاسبه موقعیت دقیق مجبور به کار روی اعداد اعشاری میشود.
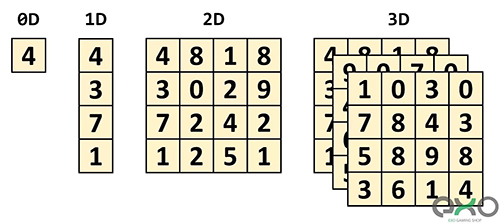
تنسور یک شیء ریاضی است که رابطه بین سایر مفاهیم ریاضی را که همه باهم پیوند دارند توصیف میکند. آنها معمولاً بهصورت آرایهای از اعداد نشان داده میشوند، جایی که بعد آرایه را میتوان بهصورت زیر مشاهده کرد.
کوچکترین تنسور تصورپذیر دارای صفر بُعد است که تنها یک مقدار را شامل میشود. به تنسور 0 بعدی اسکالر هم گفته میشود. با افزایش تعداد بُعدها، با ساختارهای مرسوم دیگر ریاضی روبهرو میشویم:
- تنسور یکبعدی: برداری
- تنسور دوبعدی: ماتریسی
به طور دقیقتر، هر تنسور اسکالر ساختار 0x0 ، تنسور برداری 1x0 و تنسور ماتریسی ساختار 1x1 دارد. برای آسانتر شدن، تنها تنسورهایی در فرم ماتریس را بررسی میکنیم. ضرب یکی از انواع مهم عملیات ریاضی است که روی ماتریسها انجام میشود.
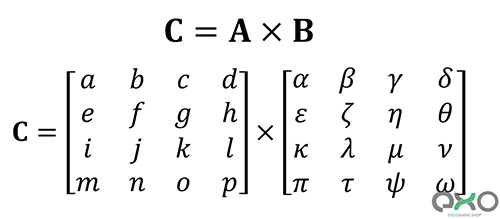
ضرب دو ماتریس با 4 سطر و 4 ستون
پاسخ نهایی ضرب ماتریسها، تعداد سطرهایش برابر با ماتریس اول و تعداد ستونهایش برابر با ماتریس دوم است. نحوه ضرب کردن دو ماتریس:
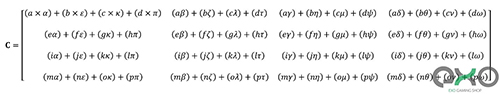
همانطور که میبینید، محاسبه یک ماتریس ساده از مجموعه کاملی از ضربها و اضافات کوچک تشکیل شده است. ازآنجاکه امروزه هر پردازنده مرکزی موجود در بازار میتواند هر دو عملیات را انجام دهد، به این معنی است که هر دسکتاپ، لپتاپ یا تبلت میتواند تنسورهای اساسی را کنترل کند.
مثال بالا 64 ضرب و 48 جمع دارد. هر ضرب کوچک مقداری را حاصل میشود که باید پیش از جمع با سه حاصلضرب بعدی، در جایی نگهداری شود. در آخر همهی آنها باید به تنسور نهایی تبدیل شوند که در جایی دیگر ذخیره خواهد شد. همه این فعالیتها ازلحاظ پردازشی فعالیتی سنگین محسوب میشود و مقادیر زیادی باید در انجام این فرایند ذخیره شوند و حافظهی کش باید خواندن و نوشتنهای زیادی را مدیریت کند.

پردازندههای AMD و Intel طی این سالها برنامههای الحاقی مختلفی را ارائه دادهاند (MMX ، SSE ، AVX - همه آنها SIMD یا چند داده با یک دستورالعمل هستند) که به پردازنده اجازه میدهد تعداد زیادی از اعداد اعشاری را همزمان مدیریت کند. دقیقاً همان چیزی که ضربهای ماتریسی نیاز دارند.
اما نوع خاصی از پردازنده وجود دارد که به طور ویژه برای مدیریت عملیات SIMD طراحی شده است: واحدهای پردازش گرافیک (GPU).
پردازشگر بسیار باهوشتر از ماشینحساب؟
در دنیای گرافیک، باید مجموعه عظیمی از دادهها در فرم برداری را در یکلحظه جابهجا و پردازش کرد. توان پردازش موازی GPUها، آنها را برای برعهده گرفتن پردازش تنسورها بسیار مناسب میکند. همهی این پردازنده از مفهوم جدیدی به نام GEMM یا General Matrix Multiplication پشتیبانی میکنند.
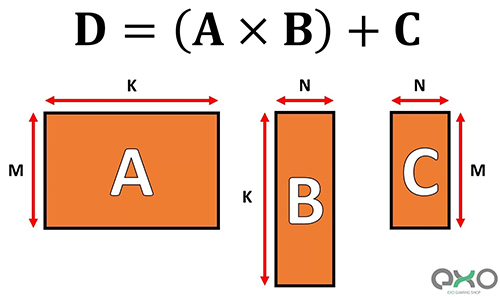
ردیفها و ستون موردنیاز برای GEMM: ماتریس A (m x k) ، ماتریس B (k x n) ، ماتریس C (m x n)
GEMM عملیاتی پیچیدهتر را انجام میدهد. در این عملیات، دو ماتریس در هم ضرب و حاصل آنها با ماتریس جدیدی جمع میکند. این سه ماتریس محدودیتهایی هم در سطر و ستون دارند که در تصویر بالا میتوانید ببینید.
الگوریتمها معمولاً در محاسبهی ماتریسهای مربعی عملکرد بهتری دارند (مثلاً ماتریس 10x10 بهتر از 2x50 خواهد بود). طبیعتاً ماتریسهای کوچکتر هم راحتتر محاسبه میشوند. بههرحال الگوریتمها بهترین عملکرد را زمانی دارند که در سختافزاری مخصوص انجام چنین محاسباتی اجرا شوند.
در 2017، انویدیا کارت گرافیکهای خود با معماری ولتا (Volta) را معرفی کرد. نکتهی مهم در این معماری، مجهز بودن پردازندههای گرافیکی مبتنی بر آن، به هستههایی مخصوص محاسبههای تنسور بود.

کارت گرافیک Titan V مجهز به تراشهی GV100 Volta
هستههای تنسور انویدیا برای انجام 64 عملیات GEMM در هر چرخهی کلاک روی ماتریسهای 4x4 طراحی شده بودند که اعداد اعشاری تا 16 بیت را پردازش کنند (FP16). دروافع، هستهها قابلیت انجام ضرب FP16 و جمع با FP32 را داشتند.
چنین تنسورهایی بسیار کوچک هستند و وقتی دیتاستهایی با ابعاد واقعی را پردازش میکنند، بلوکهای کوچک ماتریسهای بزرگتر را وارد عملیات پردازش میکنند تا با گذشت مراحل به پاسخ برسند.
انویدیا معماری تورینگ را کمتر از یک سال بعد معرفی کرد. این بار پردازندههای Geforce هم به هستههای تنسور مجهز شده بودند. ساختار به نحوی تغییر کرده بود که فرمتهای دادهای دیگر مثل اعداد صحیح 8 بیتی را هم پشتیبانی میکرد؛ البته بهجز این ساختار عملیاتی معماری تورینگ تفاوت زیادی با ولتا نداشت.

در اوایل سال جاری، معماری Ampere اولینبار در پردازندههای گرافیکی مخصوص مراکز داده A100 ظاهر شد و این بار Nvidia بهبود بیشتری در عملکرد ایجاد کرده بود (256 GEMM در هر چرخه بهجای 64)، فرمتهای داده دیگری را اضافه کرد و هستههای جدید توانایی محاسبه و مدیریت سریع تنسورهای کم پشت (ماتریسهایی با تعداد 0 زیاد) را با سرعت بالا را هم پیدا کردند.
دسترسی به این هستهها برای برنامهنویسان بسیار آسان است و با استفاده از Flag مخصوص به آنها دسترسی پیدا خواهد کرد (نوع داده باید توسط هستهها پشتیبانی شود و ابعاد ماتریس هم مضربی از 8 باشد)
تا اینجا به عملکرد مناسب و توان بالای هستههای تنسور پی بردیم حالا سؤالی که پیش میآید این است که این هستهها در محاسبه GEMM چقدر بهتر از هستههای عادی پردازندهی گرافیکی عمل میکنند؟ زمانی که معماری ولتا معرفی شد، رسانهی معتبر یک بررسی و مقایسه بین سه کارت مبتنی بر ولتا، پاسکال و ماکسول انجام دادند.
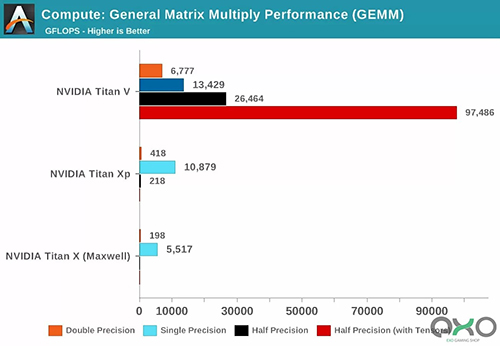
اصطلاح Precision به تعداد بیتهایی که برای اعداد اعشاری در ماتریس استفاده میشوند، اشاره دارد. double برای نشاندادن 64 و Single برای نشاندادن 32 استفاده میشود و Half هم 16 بیت را نشان میدهد.
محور افقی حداکثر عملیات اعشاری که در هر ثانیه انجام میشود را نشان میدهد که با اصطلاح FLOPS میشناسیم (به یاد داشته باشید هر GEMM بهاندازهی سه FLOP است).
فقط ببینید بهجای هستههای اصطلاحاً CUDA ، هنگام استفاده از هستههای تنسور چه نتیجهای حاصل شد! آنها بهوضوح در انجام این نوع کارها فوقالعاده هستند، بنابراین با هستههای تنسور چه کاری میتوانید انجام دهید؟
ریاضی برای بهتر کردن همه چیز
محاسبات ریاضی دنیای تنسور در فیزیک و مهندسی بسیار مفید است و برای حل انواع مشکلات پیچیده در مکانیک سیالات، الکترومغناطیس و فیزیک نجومی استفاده میشود، اما کامپیوترهایی که برای پردازش این نوع از اعداد استفاده میشدند، عملیات ماتریسی را در مجموعههای عظیمی از CPU انجام میدادند.
از حوزههای دیگری که از هستههای تنسور استفاده بسیاری در آن میشود، میتوان به یادگیری ماشین، بهویژه در زیرمجموعهی شبکهی عصبی شاره کرد. پردازشهای مرتبط در این کارها، به مدیریت مجموعههای عظیم داده که در آرایههای بسیار بزرگ شبکههای عصبی قرار دارند، نیاز است.
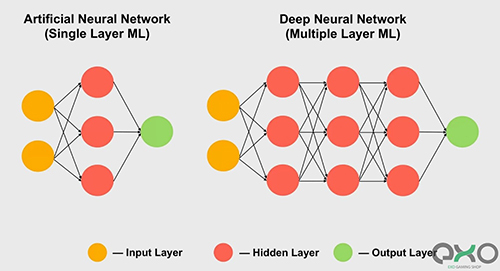
بنابراین هنگامیکه باید محاسبه یا مدیریت تعامل صدها و یا هزاران اتصال را انجام دهید، باید هر تکه از داده را در شبکه با وزنهای متفاوت از هر ارتباط ضرب کنید. به بیان دیگر، باید دو ماتریس باهم ضرب شوند که نشاندهنده همان عملیات تنسور است.

به همین دلیل است که همه ابررایانههای یادگیری عمیق از پردازندههای گرافیکی زیادی استفاده میکنند که بیشتر آنها هم ساخت انویدیا هستند. البته برخی شرکتها یکقدم فراتر رفتهاند و پردازندههای مخصوص هستهی تنسور تولید کردهاند.
برای نمونه، گوگل اولین واحد پردازش تنسور (TPU) خود را در 2016 معرفی کرد؛ اما این تراشهها بهقدری مخصوص هستند که کار دیگری بهجز محاسبههای ماتریسی انجام نمیدهند.
کاربرد هستههای تنسور در پردازندههای گرافیکی مصرفکننده (GeForce RTX)
اکنونکه به کاربرد هستههای تنسور در پردازشهای پیچیده پی بردهاید، هنوز این سؤال را مطرح میکنید: کارت گرافیک مصرفکننده مانند GeForce RTX چه استفادهای از هستهها میبرد؟ به بیان دیگر، آیا کاربر عادی که با پردازشهای سنگین فیزیک نجومی یا یادگیری ماشینکاری ندارد، واقعاً به هستهها نیاز پیدا میکند؟
بهطورکلی، هستههای تنسور برای کارهایی مانند رندر عادی یا انکود و دیکود فیلم استفاده نمیشوند. انویدیا از سال 2018 هستههای تنسور را در محصولات مصرفکننده (Turing GeForce RTX) اضافه کرد و در همان زمان، قابلیت DLSS هم عرضه شد.

فرضیه این فناوری به این صورت است: فریم در رزولوشن پایین رندر میشود و پس از پایان رندر، رزولوشن برای مطابقت با ابعاد نمایشگر افزایش مییابد (بهعنوانمثال، ابتدا در رزولوشن 1080p رندر و سپس به 1400p تغییر میکند). در این روش، با پردازش پیکسلهای کمتر، سرعت و کارایی بهتر میشود؛ اما درنهایت، بازهم با تصویری با کیفیت در نمایشگر مواجه میشوید.

اجرای بازی در رزولوشن بهتر به بهبود نمایش بافت و جزئیات تصویر کمک میکند که البته آنهمه پیکسل برای تبدیلشدن هم به پردازش نسبتاً سنگینی نیاز دارند. حال نگاه کنید که چه اتفاقی میافتد که بازی قرار است با کیفیت 1080p (25٪ پیکسل نسبت به قبل) رندر شود، اما در پایان رزولوشن به 4K افزایش یابد.

به لطف فشردهسازی jpeg و کوچک کردن تصاویر در وبسایت ما، ممکن است تفاوت فوراً آشکار نباشد، اما زره شخصیت و شکلگیری سنگها تا حدودی تار است. بیایید برای بررسی دقیقتر، بخشی را بزرگ کنیم:

تصویر سمت چپ در رزولوشن 4K رندر و تصویر سمت راست پس از رندر 1080p به 4K مقیاسدهی شده. در حرکت، به دلیل کمتر شدن جزئیات در رندر با رزولوشن کم جلوههای مات بیشتری به چشم میخورد. شاید فکر کنید این مشکل با استفاده از جلوههای شارپ کردن در درایورها قابل اصلاح باشند که چندان این راهکار را توصیه نمیکنیم!
برای رفع چنین مشکلاتی بود که فناوری DLSS کاربرد خود را نشان میدهد. در نسخهی اولیهی این فناوری، تعداد کمی از بازیها در شرایط و تنظیمات مختلف تست شدند. حالتهای گوناگون تصاویر بسیار زیادی تولید کردند که همگی وارد ابررایانههای مخصوص شدند تا با استفاده از شبکهی عصبی، بهترین روش برای تبدیلکردن تصویر 1080p به تصویری با رزولوشن بیشتر پیدا شود.

باید گفت که DLSS 1.0 عالی نبود، جزئیات در بعضی جاها از بین میرفتند و یا مشکلات مختلفی در تصاویر پیدا میشدند. همچنین این فناوری در واقع از هستههای تنسور موجود در کارت گرافیک شما استفاده نکرده (این کار در شبکه انویدیا انجام شده) و هر بازی برای پشتیبانی از DLSS برای تولید الگوریتم ارتقا نیاز به بررسی خاص خود توسط انویدیا داشت.
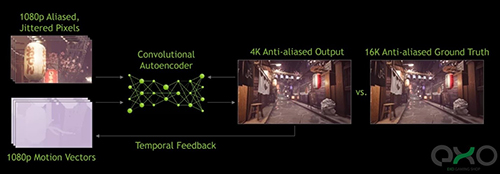
اوایل امسال نسخهی دوم DLSS با بهبودهای بسیار، معرفی شد. میتوان گفت مهمترین تغییر این بود که حالا ابررایانههای انویدیا فقط برای تولید الگوریتمهای عمومی مقیاسدهی استفاده میشدند. در نمونهی جدید DLSS، دادههای فریم رندر شده برای پردازش پیکسلها (از طریق هستههای تنسور GPU شما) با استفاده از مدل عصبی استفاده میشود.

DLSS 2.0 بسیار توانمند و کاربردی است اما متأسفانه در حال حاضر تعداد محدودی از بازیها از آن پشتیبانی میکنند. البته توسعه دهنگان قطعاً به فکر افزودن این ویژگی جذاب به نسخههای بعدی بازیها و عناوین جدید خود، خواهند بود.
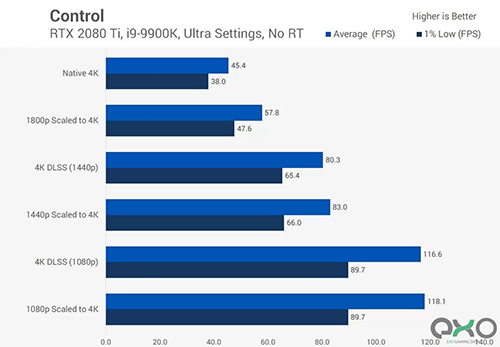
خروجی بصری DLSS همیشه بینقص نیست اما عملکرد و قدرت پردازش گرافیکی نیز بهبود پیدا میکند و توسعهدهندگان میتوانند جلوههای بصری بیشتری در اختیار کاربر بگذارند یا همان گرافیک را در طیف وسیعتری از سیستمعاملها ارائه دهند.
یکی از موقعیتهایی که DLSS کمک زیادی به تجربه بهتری از بازی میشود، هنگام فعالکردن رهگیری پرتو در بازیهای RTX enabled است. پردازندههای گرافیکی GeForce RTX دارای واحدهای جداگانه RT برای رهگیری پرتو هستند.

رهگیری پرتو نیاز به پردازشهای سنگینی دارد که در نهایت توسعه دهندگان مجبور به استفاده محدودتر از پرتوهای نوری در بازیها میشوند. در طول این پردازش ممکن است تصویر نویزدار شوند که در نتیجه نیاز به فناوری جداگانهای برای حذف نویز هم احساس میشود.
رهگیری پرتو خود بهتنهایی بهاندازه کافی سنگین بود و حالا این فناوری حذف نویز هم به سنگینتر شدن پردازشها کمک کرد. اینجاست که هستههای تنسور وارد عمل میشوند و با استفاده از الگوریتم مبتنی بر هوش مصنوعی نویز تصویر را کاهش میدهند. در نهایت با بهبودهای DLSS، هستههای تنسور میتوانند بهخوبی برای تقویت فریم ریت پس از روشنکردن رهگیری پرتو مورداستفاده قرار گیرند.
البته اینها تنها استفادههای هستههای تنسور در GeForce RTX نیست و این هستهها میتوانند به حرکت بهتر شخصیتها یا شبیهسازی بهتر لباسها هم کمک کنند. متأسفانه فعلاً راه زیادی برای بهبود و بهینهسازی استفاده از هستههای تنسور در پیش است و برای بهبودهای بیشتر تنها میتوانیم به آینده امیدوار باشیم.
در حال حاضر اینتل و AMD در پردازندههای گرافیکی خود هستههای تنسور ندارند؛ اما شاید در آینده فناوری مشابهی عرضه کنند.در این میان برخی هم هنوز معتقدند بیشتر فضای دردسترس گرافیک ها را باید به هستههای سایه زن اختصاص داد ( کاری که انویدیا در سری GTX انجام میدهد)
فروشگاه اگزوگیم عرضه کننده تمامی تجهیزات و کالاهای گیمینگ است و همچنین در کنار آن، خدماتی نظیر مشاوره رایگان فنی نیز به گیمرهای ایرانی ارائه میدهد. برای دریافت مشاوره یا هرگونه سوالی میتوانید با شماره 88226531 تماس گرفته یا به بخش دایرکت اینستاگرامِ اگزوگیم مراجعه کنید.


































































-300x300.png "موس Razer Deathadder V2")














































برای ارسال دیدگاه ابتدا باید وارد شوید.